



We keep track of everything in documents. It’s like the basic unit of information in the business setting.
But here’s the thing: I’ve worked at a place or two (not mentioning any names, but you know who you are) where the documents of which I’m supposed to stay abreast are scattered through 74 different databases, repositories, folders, and apps! I’m expected to regularly peruse Notion and Google Drive and Confluence and Dropbox and Slack and Jira and Asana and then Notion again just to find last week’s stand-up review. How shall I, the naive developer advocate in want of some critical key piece of information, find that which I seek?

But hark! Here comes our knight in shining armor: Algolia!
OK, I’ll dispense with the over-the-top language now, but in all seriousness, Algolia’s search can really help us out here. Let’s build a little tool to normalize documents from all sorts of different sources (we’ll start with Notion and Google Drive to demonstrate) and search through them with one search box.
Step 1: What makes a document?
First, we need to define what we’ll be searching through. What searchable information about a document do we need to store in our search index? Let’s list some attributes we’ll collect about each document:
- Title — It seems like the most obvious thing to search for to find a certain document is its title, no?
- Content in plaintext — Perhaps I can only remember
and metrics were 103% of forecastor some other line of jargon that was part of the article. I should be able to search for that. - Source application — We want the
performance.pptxfrom Google Docs, not from Dropbox! That one hasn’t been updated in three weeks. - Creator — What if I only remember a word or two from the title, but not enough to get good search results? Easy! Stick the creator’s name in the search query.
- Date created — This time, both
performance.pptxs are in the same place, and I need the one from yesterday and not three weeks ago. - Date last modified — We probably should allow either of these dates to be searchable since they seem equally relevant in this use case.
- URL — This seems the least relevant when it comes to the actual search, but because we don’t have a true database of all of these documents, we’re going to stick this in the search index but not make it searchable. This way, when we get our data back for display, we can make each search result an
<a>tag linking to the actual document without needing to set up that full-on database.
Perfect! Let’s actually implement this model.
Step 2: Build ourselves some drivers
I have a lot of documents in Notion, and many companies I’ve worked at do, so I’ll want to be able to search through those. So I opened up a new JavaScript file in the /functions folder of my Netlify-hosted site and added this function:
const getNotionDocs = async () => {
const { Client } = require("@notionhq/client");
const notion = new Client({
auth: process.env.TEST_NOTION_INTEGRATION_KEY
});
const db = (
await notion.databases.query({
database_id: 'e40aacb0d3824b5c991ee51d196e0e76'
})
).results;
const getPlainText = rich_text =>
Array.isArray(rich_text)
? rich_text.map(piece => getPlainText(piece)).join("")
: rich_text.plain_text;
let output = [];
for (let i = 0; i < db.length; i++) {
output.push({
objectID: db[i].id,
created_time: db[i].created_time,
last_edited_time: db[i].last_edited_time,
source_app: "Notion",
url: db[i].url,
created_by: (
await notion.users.retrieve({
user_id: db[i].created_by.id
})
).name,
content: (
await notion.blocks.children.list({
block_id: db[i].id,
page_size: 50
})
)
.results
.map(result => result[result.type].rich_text)
.map(getPlainText)
.join("\n"),
title: db[i].properties.Name.title[0].plain_text
});
}
return output;
};
This actually consumes a database contained right here in this article! I’m writing this article in Notion, and the database that this code is reading is right after this line.
In production, I’d obviously make that read the company’s Notion database of relevant documents that I want to search through, but for demonstration, I’ve just made it a silly mock list of Star Wars quotes.
I’m also going to build a similar driver for Google Drive:
const getGoogleDriveDocs = async () => {
const fetch = require("node-fetch");
const { extractText } = require('node-extract-text-from-file')
const folder_id = '11lBok_A_vfWTNfLTBGJbioT4JLiX52BM';
const response = await fetch(
`https://www.googleapis.com/drive/v3/files?key=${process.env.GOOGLE_DRIVE_KEY}&q=%22${folder_id}%22+in+parents&fields=files(id,name,webContentLink,createdTime,modifiedTime,owners,webViewLink)`
);
const fileList = (await response.json()).files;
let output = [];
for (let i = 0; i < fileList.length; i++) {
output.push({
objectID: fileList[i].id,
created_time: fileList[i].createdTime,
last_edited_time: fileList[i].modifiedTime,
source_app: "Google Drive",
url: fileList[i].webViewLink,
created_by: fileList[i].owners[0].displayName,
content: (await extractText({ fromUrl: fileList[i].webContentLink })).text,
title: fileList[i].name
})
}
return output;
};
Just to give a little context on this one: Google Drive, as you might expect, doesn’t have its own filetype like Notion does, so I’m just assuming that the filetype is DOC, DOCX, or PDF. That means I can feed the download link that Google Drive returns through this helpful NPM package, and voila! I have the plaintext content of the document. That plaintext is by no means pretty, but it’s useful for searching through. We don’t have to make it look good since nobody will ever see it.
At the end of the file, we have the actual Netlify Function part:
exports.handler = async ev =>
ev.httpMethod != "GET"
? { statusCode: 404 }
: {
statusCode: 200,
body: JSON.stringify({
notion: await getNotionDocs(),
google_drive: await getGoogleDriveDocs()
}, null, '\t')
};
In plain English: if we ping this endpoint with a GET request, it’ll get all relevant documents from Notion and all relevant documents from Google Drive, compile them into one neat array of search-ready document objects, and return it to us as stringified JSON — our search index data!
Step 3: Update our index regularly
So now, we just have to get this data to Algolia! To do this, I’ve going to make use of an experimental feature in Netlify called Scheduled Functions. There’s more detail in the article I just linked, but in short, instead of just exporting our lambda function as usual, we pass it through a schedule function exported by Netlify first. It’ll be easier to explain through demonstration — if you’re following along, make sure you’ve npm installed the @netlify/functions module. Then that last code sample I shared will change to look more like this:
const { schedule } = require('@netlify/functions');
const algoliasearch = require('algoliasearch');
exports.handler = schedule("@daily", async ev => {
const client = algoliasearch('REDACTED-PROJECT-ID', 'REDACTED-API-KEY');
const index = client.initIndex('documents');
const documents = [
...(await getNotionDocs()),
...(await getGoogleDriveDocs())
];
index.saveObjects(documents);
return {
statusCode: 200,
body: JSON.stringify(documents, null, '\t')
}
});
This function will run every day, pulling all the documents from Notion and Google Drive and submitting it to Algolia.
Step 4: Searching through our index
Next up is the GUI!
I didn’t put very much effort into this, as it’s made rather simple with the Algolia InstantSearch React Hooks module. Here’s what it looks like while searching:
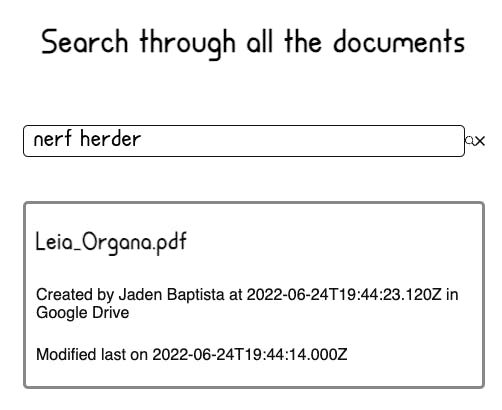
And while not searching:

And while not meaningfully searching:

Here’s the whole page component (in Next.JS):
import Head from 'next/head';
import algoliasearch from 'algoliasearch/lite';
import { InstantSearch, SearchBox, Hits } from 'react-instantsearch-hooks-web';
import styles from '../styles/document-search.module.css';
const searchClient = algoliasearch('PROJECT_ID', 'API_KEY');
const DocumentSearch = () => {
return (
<>
<Head>
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/instantsearch.css@7.3.1/themes/reset-min.css" integrity="sha256-t2ATOGCtAIZNnzER679jwcFcKYfLlw01gli6F6oszk8=" crossorigin="anonymous" />
</Head>
<InstantSearch searchClient={searchClient} indexName="documents">
<main id={styles.container}>
<h1>Search through all the documents</h1>
<SearchBox />
<Hits hitComponent={({hit}) => (
<a
className={styles.hit}
href={hit.url}
>
<h2>{hit.title}</h2>
<span>Created by {hit.created_by} at {hit.created_time} in {hit.source_app}</span>
<span>Modified last on {hit.last_edited_time}</span>
</a>
)} />
</main>
</InstantSearch>
</>
);
}
export default DocumentSearch;
If you’re not familiar with InstantSearch, Algolia provides several widgets that contain the most common pieces of search UI and functionality. For example, there’s a default SearchBox component which displays an input box and pings Algolia’s servers with the query any time the value of the <input> changes. The <Hits> component gets updated every time those queries return data, and it displays each hit as the component you give it as a prop. These are, of course, available in more forms than React components — see the InstantSearch docs for more details.
Step 5: Profit (or, you know, get less annoyed)
It can get nearly impossible at times to keep track of all the places we store information. In the end, that’s what search is for — when there’s too much data to digest at once and easily find what you’re looking for, we need to filter what we’re looking at. Now that we’ve done this for the myriads of documents that plague many a remote engineer, we’ll never lose a document again (until we add another document store that is… but we can always add more drivers). If you want to check out this little proof-of-concept in practice, it’s here on my personal site!
Decentralization is a controversial word nowadays, but with important work materials, I think we can all agree it’s unequivocally bad. If you’re up for staving off the decentralization of your own documents, you can get started today with Algolia! Thanks for reading, and I’ll check back in with another fun Algolia project shortly!